
Giungiamo ora, con questa guida, al termine del nostro viaggio all’interno delle opzioni del software ufficiale di Scrapebox e dell’analisi delle sue sezioni principali.
Concludiamo quindi con le ultime due: Comment Poster e Manage List
RICORDA: prima di continuare nella lettura, come per le altre guide, è fondamentale che tu approfondisca alcuni argomenti di ScrapeBox e nello specifico quelli che riguardano l’impostazione di un motore di ricerca avanzato e la scelta e l’implementazione di un servizio di proxies
Indice: Guida a ScrapeBox: Manage Lists
1.0 Sezioni di ScrapeBox – 1: Comment Poster
2.0 Sezioni di ScrapeBox – 2: Manage Lists
2.1 Funzioni di Manage Lists: Remove Filter
2.2 Funzioni di Manage Lists: Trim…
2.3 Funzioni di Manage Lists: Check Metrics
2.4 Funzioni di Manage Lists: Check Indexed
2.5 Funzioni di Manage Lists: Grab / Check
2.6 Funzioni di Manage Lists: Import URL List
2.7 Funzioni di Manage Lists: Export URL List
2.8 Funzioni di Manage Lists: Import/Export URL’s & PR
2.9 Funzioni di Manage Lists: More List Tools
2.10 Update
Sezioni di ScrapeBox – 1: Comment Poster
Si tratta di una sezione ben specifica e nella guida che ti presentiamo ha un ruolo assolutamente marginale. La tratteremo quindi in modo non approfondito ma elencando solo le principali funzionalità.

Sezione Comment Poster
In sostanza: questa sezione permette di impostare e gestire l’automatizzazione dei commenti avendo a disposizione nomi, e-mails, siti e domini.
Sezioni di ScrapeBox – 2: Manage Lists
Affrontiamo ora, invece, una delle sezioni realmente fondamentali di ScrapeBox: Manage Lists.
Si tratta dell’insieme di tutte quelle funzioni e filtri che ti permettono di operare direttamente online sui risultati ottenuti in fase di ricerca e di scraping. Risultati che sono sempre elencati nella corrispondente sezione Url’s Harvested e le cui funzionalità hai già potuto approfondire in nella precedente guida su ScrapeBox.

Manage Lists
Analizziamo ora nello specifico tutte le voci del menu Manage Lists:
Torna all’indice della sezione
Funzioni di Manage Lists: Remove Filter
Questa funzionalità ha, come per tutte le altre, alcune sotto voci:

Remove / Filter
Remove Duplicate Url’s: partendo da una lista di URL’s trovate in fase di scraping, vengono eliminate tutte quelle che sono duplicate.
NOTA: per controllare, in prima istanza, se ci sono dei duplicati eliminati si può semplicemente controllare il numero totale di URL’s annotate in fondo alla sezione URL’s Harvested prima e dopo aver applicato questo filtro. La dicitura è Url’s in list.
Remove Duplicate Domains: invece di rimuovere le singole URL duplicate, agisce sul dominio ed elimina quelli ripetuti. Come nel caso precedente è possibile controllare il numero tramite l’Url’s in List
Remove Entries witch are not URL’s: elimina tutte le url che non contengono inizialmente http:// o https://
Split Duplicate Domains: salva all’interno di un file di testo .txt tutti i duplicati dividendoli alfabeticamente in base al dominio.
NOTA: questa operazione deve essere eseguita prima di eliminarli con le funzioni precedenti.
Remove Url’s Containing…: consente di rimuovere tutte le URL’s che contengono una lettera o un termine presente nella lista di URL’s. Questa condizione viene impostata nel successivo campo di input Mask che viene mostrato, dopo aver cliccato sul pulsante, all’interno di una finestra di popup.
ATTENZIONE: digitando, all’interno del campo Mask, un semplice spazio vuoto questa funzione cancella tutte le URL’s che contengono questo carattere specifico
Remove Url’s not Containing…: specularmente alla voce precedente consente di rimuovere tutte le URL’s che non contengono una lettera o un termine all’intero della lista trovata in fase di scraping.
Remove Url’s containing entries from…: consente di rimuovere tutte le URL’s che contengono una lettera o un termine comune all’interno della lista trovata e caricando queste condizione da un file di testo esterno realizzato in formato .txt
Remove Url’s not containing entries from…: similmente alla voce precedente consente di rimuovere tutte le URL’s che non contengono una lettera o un termine all’intero della lista trovata. Queste condizioni vengono caricate da un file di testo esterno realizzato in formato .txt
Remove Url’s with more than XXX words: rimuove tutte le URL’s formate da un numero maggiore di “n” lettere del tipo alfanumerico.
Remove Url’s with less than XXX words: rimuove tutte le URL’s formate da un numero minore di “n” lettere di tipo alfanumerico.
Remove Subdomain from URL’s: rimuove tutti le URL’s che contengono sottodomini sempre partendo dal path o root principale.
Remove URL’s with extension…: rimuove dalla lista delle URL’s trovata in fase di scraping tutte quelle che hanno un’estensione specifica. Queste particolari estensioni (esempio: .mp3, .pdf, .swf, etc) vengono mostrate in una finestra che si apre subito dopo aver cliccato sul pulsante.
Si tratta di un campo input che può essere quindi modificato o integrato a secondo delle necessità specifiche.
Apply Cloud Blacklist: rimuove dalla lista tutte le URL’s registrate in una blacklist memorizzata in un servizio Cloud di tua scelta.
Apply User’s Local Blacklist: rimuove dalla lista tutte le URL’s registrate in una blacklist impostata localmente nei settaggi di ScrapeBox.
Torna all’indice della sezione
Funzioni di Manage Lists: Trim…
Questa funzione ha tre sotto voci

Trim
Trim to Root: permette di “ripulire” le URL’s trovate in fase di scraping mantenendo unicamente la root principale.
Esempio: http://www.sito1.com
Trim to Last Folder: permette di eliminare tutte le directory segnate nelle URL’s ad esclusione di quella precedente alla root principale del sito
Esempio: http://www.sito1.com/ultimadirectory/
Trim Urls to Domain Level: permette di eliminare tutti i vari parametri dalle URL’s mantenendo unicamente il nome del dominio e l’estensione
Esempio: sito1.com
Torna all’indice della sezione
Funzioni di Manage Lists: Check Metrics

Check Metrics di Yandex
Questa sezione permette di gestire i dati e le metriche di navigazione di Yandex che è un motore di ricerca specifico russo e quindi caratteristico di quel mercato nazionale.
Gestisce due sotto voci che sono:
Get URL Metrics from Yandex: permette di acquisire e analizzare i dati riferiti alle URL’s oggetto di scraping e harvesting e riferiti alla metrica TCY-U e allo status della URL.
Get Domain Metrics from Yandex: permette di acquisire e analizzare i dati riferiti ai Domini oggetti di scraping e harvesting e riferiti alla metrica TCY-U e allo status della URL.
Torna all’indice della sezione
Funzioni di Manage Lists: Check Indexed

Il Check Indexed del Manage Lists di ScrapeBox
Questa sezione del Manage Lists permette di gestire le metriche di ricerca su tre motori di ricerca partendo sempre dall’elenco di URL’s presenti nel campo Url’s Harvested: Google, Bing e Yahoo.
Una volta che tutte le URL’s sono state trovate è possibile, premendo sul corrispondente motore di ricerca, iniziare la scansione dei contenuti indicizzati. Cliccando sul pulsante Start / Redo, utilizzando sempre i Proxies, sarà possibile vedere lo status di indicizzazione della singola URL.
L’intestazione della colonna di conferma di indicizzazione (YES o NO) varia a seconda del motore selezionato: IDX-G per Google, IDX-B per Bing, IDX-Y per Yahoo.

Indexed Checker del Manage Lists
Torna all’indice della sezione
Funzioni di Manage Lists: Grab / Check

Grab / Check di Manage Lists
Questa nuova sezione del Manage Lists di ScrapeBox permette di trovare e catturare alcuni parametri ben specifici partendo da una serie di URL’s o da una lista di domini.
Nello specifico troviamo 12 sottovoci che andiamo adesso a elencare con più precisione:
Grab emails from Local List: permette di trovare e di restituire l’elenco di email partendo da un file che viene caricato esternamente e presente sul PC dell’utilizzatore.
Sono supportate alcune estensioni: .txt (testo), .htm e .html (file web), .sql (file di database), .csv (file generici di fogli elettronici).
Una volta completata la procedura di controllo (Check) il totale numerico delle email trovate viene restituito a video ed è possibile esportare un file di testo che le contiene tutte.
Grab emails by Crawling Sites: si tratta di un’opzione molto ben strutturata. In sostanza ricalca l’opzione precedente come funzionalità base ma la espande con altre opzioni molto potenti
Partendo da una singola URL, che può essere inserita nell’apposito campo Site oppure da una lista di url’s trovate durante la fase di harvesting, è possibile scansionare questi siti alla ricerca di indirizzi di posta elettronica.
Sono aggiunte, appunto, alcune ulteriori e utili opzioni quali:
1) la possibilità di scegliere fino a quale livello di profondità Depth nella struttura ad albero del sito cercare le emails settando la casella corrispondente con un numero che rappresenta il livello numerico (1=root del sito; 2,3,4,n=livelli sempre più bassi con nuove pagine e nuove emails trovate);
2) il ritardo Delay dell’utilizzo dei Proxies in modo tale da non rischiare il ban degli stessi (None=nessun ritardo, Fixed=valore in ms impostato dalla casella numerica successiva Fixed, Random=valore non fissato ma impostabile tra uno massimo e uno minimo nelle caselle numeriche successive Random between e and);
3) una casella numerica di default settata su 0 e quindi non attivata che imposta i tentativi Proxies Retries da ripetere ciclicamente nella ricerca;
4) un pulsante Data Folder che permette di scaricare in una directory del PC la lista in formato .txt delle emails trovate;
5) la possibilità di salvare in Options non solo le emails ma anche le URL nella quali sono state trovate;
6) un Set Filter all’interno del quale è possibile applicare ulteriori filtri sia sulle emails da rimuovere Remove emails containing che da considerare Keep emails containing.

Grab emails da harvested urls in ScrapeBox
Grab phone numbers from harvested URL List: in modo simile alla precedente sotto voce questa opzione permette di ricavare, tramite una successiva maschera con altre impostazioni, i numeri telefonici partendo da una lista di URL’s. Questa lista è quella che viene caricata dal campo principale della sezione Url’s Harvested.
Le impostazioni sono:
1) Save URL’s with extracted data che permette di salvare nel file di riepilogo dei numeri telefonici anche la corrispondente URL dalla quale proviene;
2) Show data folder che riepiloga tutti i files .txt che contengono i dati trovati. Questi files si trovano di default all’interno della cartella inserita in questo percorso …/scrapebox64/Grabbed Data/Phone Numbers;
3) Configure Masks che permette di settare in modo più preciso la maschera d’estrazione dei dati telefonici dalla singola URL trovata. Si possono creare delle matrici di maschere in modo da utilizzarle più volte e in modo da poter decidere quale di esse sia considerabile di default;
4) Settings che permette di settare due valori fondamentali e cioè quelli del Timeout in secondi e quello del numero massimo di Connections da utilizzare durante la ricerca.

Grab numeri telefonici
Grab comments from harvested URL List: come per le opzioni precedenti questa voce permette di cercare ed estrapolare all’interno di una lista di URL’s presenti nella sezione di Harvesting tutti i commenti presenti.
Questa operazione ha in effetti una ridotta valenza SEO ed è utilizzata per trovare commenti su siti.
E’ possibile settare diverse piattaforme all’interno delle quali estrapolare i commenti. Di default sono settate la piattaforma di WordPress.org e quella di vBulletin. Nelle opzioni avanzate gestite tramite il pulsante Platform Configuration puoi crearne e settarne delle altre in modo molto semplice e intuitivo.

Grab Check Manage List
Grab META info from harvested URL List: se vuoi cercare e trovare all’interno della lista inserita nella sezione di Url’s Harvested tutti i META tag <title>, <description> e <keywords> puoi usare questa sottovoce.

Grab Meta Tag – Manage List
Il programma cerca all’interno delle URL’s questi tre dati e successivamente li restituisce a video divisi per colonne univoche.
E’ possibile poi scaricare questo elenco in comodi files del tipo .cvs, .xlsx o .txt per poter successivamente analizzare i dati ottenuti.
Prima di questa opzione è possibile filtrare ulteriormente i dati trovando e eliminando tutte le URL’s che non restituiscano valori/dati tra il title, la description o le keywords. Oppure eliminare anche tutte le URL’s selezionate

Grab Meta Tag Filter
Grab links by crawling a site: è possibile impostare nel campo di input Site (http://… or https://…) l’indirizzo URL di un qualsiasi sito del quale si vogliono catturare i links. Questi ultimi verranno restituiti nella finestra principale e saranno consultabili anche aprendo il file .txt indicato in fondo alla pagina in corrispondenza alla voce Links saved as:
E’ possibile anche determinare la profondità di ricerca dei links impostando il livello corrispondente: da 1 fino a un massimo di 20.

Grab links by crawling a site
Grab YouTube Video: –
Grab images from harvested URL List: permette di catturare e scaricare le immagini partendo direttamente da una lista di URL’s trovate in fase di harvesting delle keywords.
Il programma analizza tutte le URL’s e successivamente scarica le immagini trovate all’interno di una cartella del PC.
E’ possibile impostare questa ricerca e il successivo download direttamente dalle tab Settings all’interno della quale scegliere tutti i parametri ritenuti necessari per un migliore settaggio della ricerca.

Settings di Grab links by crawling a site
Grab keywords from harvested List: partendo da un elenco di URL’s questa sezione del programma analizza tutti i siti e i domini alla ricerca delle keywords presenti.
Prima di dare inizio alla ricerca è prevista la possibilità di settare, con la tab Settings, ulteriori opzioni relative alle parole da cercare e più precisamente:
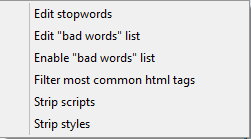
1) Edit stopwords che contiene un elenco di termini da non considerare;
2) Edit Bad words list, un campo di input che permette di aggiungere termini, parole o sostantivi da non considerare nella ricerca;
3) Enable bad words list che attiva una lista esterna di parole da non considerare nella ricerca;
4) Filter most common html tags che permette di filtrare i principali tags html da un elenco già impostato;
5) Strip scripts e 6) Strip styles –
Successivamente si può scaricare questo elenco in un file di testo oppure salvarlo nella sezione iniziale dell’Harvester and Keywords per una successiva azione di ricerca.
Grab files: permette di cercare files all’interno del solito elenco di URL’s individuato nella fase di harvesting. E’ possibile anche effettuare questa ricerca in un solo sito ma in questo caso è necessario non selezionare l’opzione Use harvested list bensì inserire l’indirizzo url del sito da controllare.

Grab files
E’ possibile anche impostare la tipologia (estensioni) di files da controllare e scaricare attraverso la tab Settings

Settings di Grab files
Check Unregistered Domains: permette di controllare lo status dei domini oggetto dell’harvesting e di determinare se risultano liberi o meno. Possono essere opportunamente settati sia i DNS da controllare che l’opzione corrispondente al Whois.

Check Unregistered Domains
Custom Data Grabber: questa ultima voce è utilissima in quanto permette di creare un motore di grabbing customizzato e quindi personalizzato. Utile per ogni evenienza e per ulteriori ricerche non comprese nelle voci appena evidenziate.

Custom Data Grabber
Torna all’indice della sezione
Funzioni di Manage Lists: Import URL List

Import URL List
Affrontiamo ora nuove funzionalità del Manage List di ScrapeBox descrivendo le voci della Tab Import URL List.
Sono nello specifico:
Import and Replace Current List: permette di caricare dal PC dell’utilizzatore un file di testo che contenga una lista di URL’s che vanno a sostituire, se eventualmente presenti, quelle inserite nella finestra principale dell’Url’s Harvested.
Import and Add to Current List: similmente alla voce precedente carica le URL inserite all’interno di un file di testo e le aggiunge a quelle già presenti nell’Url’s Harvested.
Import from Cloud Storage: importa una lista di URL’s memorizzate in un servizio online di Cloud. Si può scegliere tra DropBox, OneDrive, Box.net o GDrive.
Select the URL’s List to Compare: partendo da quanto trovato con l’Url’s Harvester è possibile confrontare questa lista con una importata da un file esterno rigorosamente in formato .txt
Una volta confrontate queste due liste verrà mostrato a video solo quelle URL’s uniche.
Select the URL’s List to Compare on Domain Level: similmente all’opzione precedente è possibile confrontare due liste di URL’s per desumere quale dominio è ripetuto eliminandolo se presente.
Paste/Replace from Clipboard (replace current list): copia e sostituisce la lista di URL’s con l’ultimo contenuto degli appunti del PC.
Paste/Add from Clipboard (append to existing list): copia e aggiunge alla lista già presente il contenuto degli appunti del PC.
Torna all’indice della sezione
Funzioni di Manage Lists: Export URL List

Export URL List
Eccoci giunti alla TAB del programma che permette di gestire l’esportazione di quanto trovato con l’URL’s Harvesting. Queste sono le singole voci:
Export all URL’s as Text: permette di esportare tutte le URL’s in un file di testo nominandolo o rinominandolo a piacere.
Append all URL’s to existing file: permette di aggiungere a una lista già salvata sul PC dell’utente una nuova lista di URL’s
Copy all URL’s to Clipboard: aggiunge l’elenco dell URL’s agli appunti del PC
Export as Excel file: esporta le URL’s con un formato compatibile con Excel o LibreOffice Calc.
Export as HTML: esporta le URL’s con una formattazione leggibile offline con un qualsiasi browser internet. E’ possibile caricare fino a 1.000.000 di URL’s creando anche, oltre al file che contiene tutti i link, un semplice file index.html che permette di linkare il file html generale.
Export and Split: –
Export and Randomize: esporta le URL’s ordinandole in modo casuale.
Export all URL’s as URL Encoded ANSI File: esporta le URL’s impostandole secondo le direttive dichiarate da questo formato standardizzato.
Export all URL’s to Cloud Storage: esporta le URL’s memorizzandole all’interno di un servizio Cloud. Si possono scegliere tra questi operatori: DropBox, OneDrive, Box.net e GDrive.
Export as RSS XML List: questa funzione permette di creare un file .xml valido per gli RSS partendo dalla lista delle URL’s trovate durante la fase di harvesting.
Per poter creare questo file è necessario settare i valori che verranno analizzati e i campi saranno: title e description.
Nella finestra che si apre dopo aver cliccato sul pulsante corrispondente bisogna per prima cosa settare il nome delle voci che verranno esportate e che creano il file .xml e nello specifico: title, url e description.
Si possono usare i titoli che si preferisce lasciando anche al programma la scelta di default proposta.
Successivamente inizia a fase di controllo che una volta completata restituisce una serie di risultati filtrabili ancora con la funzione Filter per eliminare sia i link evidenziati che quelli che risultano con un status code differente dal 200.
Export as SiteMap XML List: questa funzione genera una sitemap in formato .xml partendo da tutte le URL’s trovate. E’ utile quindi per realizzare una sitemap sui link interni di un sito sottoposto a scraping e harvesting. Alcune opzioni devono essere aggiunte prima della creazione e nello specifico bisogna segnalare nella sitemap questi parametri:
1) indicare le data di ultima modifica delle URL’s;
2) indicare il valore di priorità delle URL’s;
3) indicare la frequenza di aggiornamento dei contenuti della sitemap.
Export indexed URL’s: –
Export not indexed URL’s: –
Export all index checker URL’s as Excel .xlsx file: questa voce permette di esportare in formato Excel .xlsx (quindi anche visualizzabile con altri lettori di fogli di calcolo come Calc di LibreOffice) quante risorse sono indicizzate in riferimento alla URL segnata.
Export and split based on tld: questa voce opera un controllo sulle URL’s trovate in fase di harvesting e successivamente divide tutte le estensioni TLD creando un singolo file di testo per ogni estensione.
Esempio: se abbiamo 10 URL’s del tipo .net, .org, .it, .ch, .uk il programma crea 5 file .txt all’interno dei quali raggruppa tutte le TLD uguali.
Torna all’indice della sezione
Funzioni di Manage Lists: Import/Export URL’s

Import/Export URL’s
Import As Text: questa voce permette di esportare le metriche di ScrapeBox come un file di testo salvandolo nella sezione indicata sull’hard disk
Esport As Excel XLSX File: questa voce, similmente alla precedente, permette di esportare le metriche di ScrapeBox come un file Excel o Calc.
Import From Text: questa voce permette di caricare le metriche direttamente da un file di testo.
Torna all’indice della sezione
Funzioni di Manage Lists: More List Tools

More List Tools
Questa voce permette di effettuare ulteriori filtraggi sulla lista di URL’s trovate durante l’harvesting. Nello specifico:
Platform popularity: controlla la percentuale di presenza delle varie URL’s all’interno di alcune piattaforme di blogging restituendo i valori trovati.
Le principali piattaforme impostate di default sono: WordPress Blog, BlogEngine, etc. Sono considerate, comunque, circa 35 piattaforme comuni.
Una volta completato questo controllo è possibile esportare i risultati sia in un solo file di testo che in più files .txt divisi per piattaforma (operazione gestita automaticamente da ScrapeBox.
Randomize harvester urls: ordina tutte le URL’s trovate durante l’harvesting in modo casuale.
Prefix urls in harvester grid with http://: –
Torna all’indice della sezione
Update

Update
Questa voce permette di controllare, ed eventualmente aggiornare all’ultima versione stabile, il software ScrapeBox. Abbiamo già visto questa opzione nella guida introduttiva.