
Analisi dei Log File del Server: Guida all’ottimizzazione SEO
L’analisi dei log è una pratica cruciale per l’ottimizzazione SEO, focalizzata sulla scansione e indicizzazione efficiente del sito web. I log file registrano ogni interazione tra il server e i visitatori, inclusi i crawler dei motori di ricerca, offrendo dati preziosi per comprendere il comportamento dei bot sulle pagine.
Utilizzando queste informazioni, è possibile migliorare la struttura del sito, ottimizzare il crawl budget e risolvere problemi di accessibilità. In questo articolo esploreremo come sfruttare l’analisi dei log per potenziare la SEO, garantendo una presenza online più visibile e performante.
Indice articolo - Analisi dei Log File del Server: Guida all’ottimizzazione SEO
- Tipologie di Log del Server
- Analisi dei Log: download e sintassi
- Panoramica sugli strumenti
- Monitoraggio di googlebot e degli altri crawler
- A cosa servono i Log?
- Identificare bot e richieste di spoofed search bot
- Velocità di scoperta degli URL
- Frequenza di scansione e ottimizzazione del crawl budget
- Profondità della scansione e frequenza nelle subdirectories
- Pagine no index o bloccate dal robots.txt
- Ottimizzare le pagine lente e di grandi dimensioni
- Scoprire e gestire le orphan pages
- Identificazione degli status code
- Risposte inconsistent response
- Audit redirect e risorse inesistenti
- Scansione del crawl hidden e spazi infiniti
- Full recrawl: quando e perché
- Best Practices per la SEO Log Analysis
- Importanza della registrazione sequenziale e cronologica delle operazioni
- Perché implementare la Log Analysis nella strategia SEO?
Tipologie di Log del Server
I server web generano diversi tipi di file di registro, ognuno dei quali fornisce informazioni specifiche su vari aspetti del funzionamento e delle interazioni del sito. Comprendere le diverse tipologie di log è essenziale per sfruttarli al meglio nella gestione e ottimizzazione del sito web. Scopriamo i principali:
- Access Log: registrano tutte le richieste di accesso alle risorse del server. Ogni volta che un utente o un bot visita una pagina del sito, questa azione viene documentata in un access log, fornendo dettagli come il metodo di richiesta (GET o POST), l’URL richiesto e lo status code della risposta del server.
- Error Log: documentano tutti gli errori che si verificano durante l’interazione con il server. Questi dati sono essenziali per individuare problemi come errori che restituiscono uno status code 404 (pagina non trovata) o 500 (errore interno del server), aiutando a risolvere rapidamente i malfunzionamenti, errori e problemi di varia natura, migliorando l’esperienza utente.
- Security Log: registrano eventi di sicurezza, come tentativi di accesso non autorizzati o attacchi informatici. Questi log sono cruciali per monitorare la sicurezza del sito e adottare misure preventive contro potenziali minacce.
- Application Log: sono specifici per le applicazioni in esecuzione sul server e registrano eventi rilevanti per il funzionamento dell’applicazione stessa. Questi dati possono includere dettagli su operazioni di database, attività di utenti all’interno dell’applicazione, e messaggi di debug.
- Custom Log: possono essere configurati per tracciare informazioni specifiche in base alle necessità del sito o dell’organizzazione. Possono includere dettagli aggiuntivi non presenti nei log standard, fornendo una maggiore granularità di dati per analisi più approfondite. La personalizzazione permette di adattare la raccolta dei dati alle esigenze particolari del progetto.
Analisi dei Log: download e sintassi
Per procedere con l’analisi dei file di registro, è necessario prima accedere al server e scaricarli. I log sono generalmente archiviati sul server web che ospita il sito e possono essere raggiunti attraverso il pannello di controllo dell’hosting, tramite FTP o SSH, a seconda del livello di accesso amministrativo disponibile.
Alcuni provider di hosting offrono strumenti integrati per il download diretto, in altri casi, potrebbe essere necessario decomprimerli, poiché spesso sono compressi per risparmiare spazio.
Inoltre, è importante considerare che i log possono essere frammentati su più server o distribuiti attraverso una Content Delivery Network (CDN). In scenari di bilanciamento del carico, dove il traffico del sito è distribuito tra diversi server, i log potrebbero essere sparsi su ciascuno di essi. Questo rende necessaria la raccolta dei file da ogni server, per avere una visione completa e accurata delle attività del
Assicurarsi di avere accesso a tutti i file di log pertinenti, indipendentemente da dove siano archiviati, è fondamentale per un’analisi completa e accurata.
Per assicurarsi un audit del log del server efficace, se non si possiede esperienza nello scarico o si lavora come SEO freelance all’interno di un team variegato, il consiglio è chiedere supporto agli amministratori di sistema.
Sintassi dei File di Log
I file di log seguono una struttura specifica che permette di organizzare e interpretare facilmente le informazioni registrate. Ecco un esempio della sintassi:
123.456.789.000 – – [01/Jan/2024:00:00:01 +0000] “GET /index.html HTTP/1.1” 200 5324 “https://example.com” “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36”.
Questa riga contiene diverse informazioni chiave:
- Indirizzo IP: identifica l’origine della richiesta.
- Timestamp: indica la data e l’ora esatte della richiesta.
- Metodo di richiesta: specifica il tipo di richiesta HTTP (ad esempio, GET o POST).
- URL richiesto: mostra quale risorsa è stata richiesta.
- Codice di stato HTTP: indica l’esito della richiesta (ad esempio, 200 per successo, 404 per pagina non trovata).
- Dimensione della risposta: numero di byte inviati in risposta.
- Referer: URL della pagina da cui proviene la richiesta.
- User Agent: dettagli sul browser e il dispositivo utilizzati per effettuare la richiesta.
Inoltre, una registrazione accurata aiuta a correlare eventi diversi, come picchi di traffico con errori di server, migliorando la capacità di risolvere rapidamente le problematiche e ottimizzare le performance del sito.
Panoramica sugli strumenti
Per una migliore gestione dei log del server, esistono diversi strumenti specializzati che offrono funzionalità avanzate. Tra i più utilizzati troviamo Screaming Frog SEO Log File Analyser, che permette di esaminare dettagliatamente le attività di crawling dei motori di ricerca. Altri strumenti noti includono ELK Stack (Elasticsearch, Logstash, Kibana), una soluzione completa per l’aggregazione, l’analisi e la visualizzazione dei dati, e Splunk, una piattaforma potente per la ricerca e il monitoraggio dei log.
Questi strumenti sono essenziali per trasformare i dati grezzi dei file di log in informazioni utili per i consulenti SEO.
Oltre ai software di terze parti elencati, è possibile utilizzare la riga di comando per esaminare i file di log, anche di grandi dimensioni. Soluzioni come grep permettono di cercare e filtrare specifiche informazioni all’interno dei log, facilitando l’identificazione rapida di pattern o errori. Questo metodo è particolarmente utile per un’analisi preliminare o per chi preferisce un approccio più manuale e diretto di analisi dei dati.
Possiamo effettuare la server log analysis SEO ricorrendo ai due differenti approcci applicabili all’analisi dei log: l’analisi in tempo reale e l’analisi non in tempo reale. Entrambi i metodi offrono vantaggi specifici e possono essere scelti in base alle esigenze e agli obiettivi strategici del progetto SEO.
Analisi in tempo reale
L’analisi in tempo reale consente di monitorare le attività sul sito web non appena si verificano. Graylog e Kibana, offrono dashboard in tempo reale per la visualizzazione dei dati di log appena vengono generati. Questo tipo di analisi è particolarmente utile per rilevare immediatamente eventuali problemi critici, come errori di server o attacchi di sicurezza, permettendo interventi rapidi per mitigare i danni.
L’analisi in tempo reale offre anche la possibilità di monitorare il comportamento dei crawler e degli utenti in tempo reale, fornendo dati aggiornati per decisioni tempestive su ciò che sta accadendo.
Analisi non in tempo reale
L’analisi dei log non in tempo reale, invece, si basa su una revisione periodica dei dati raccolti. Questa metodologia permette di analizzare ed esaminare trend a lungo termine e identificare pattern ricorrenti. Strumenti come AWStats e Log Parser di Microsoft, oltre al citato log file analyser di Screaming Frog, sono ideali per questo tipo di analisi, consentendo di elaborare grandi quantità di dati storici e di generare report dettagliati.
L’analisi non in tempo reale permette di pianificare interventi strategici basati su dati consolidati, migliorare l’architettura del sito, ottimizzare il crawl budget (CBO) e risolvere problemi di indicizzazione che emergono solo su un periodo prolungato.
Per chi volesse fare un po’ di pratica, senza installare strumenti particolari, è possibile utilizzare Excel per un primo approccio. Excel offre funzionalità utili per filtrare, ordinare e analizzare i dati dei log, rendendo più accessibile l’esplorazione delle informazioni contenute nei file di registro.
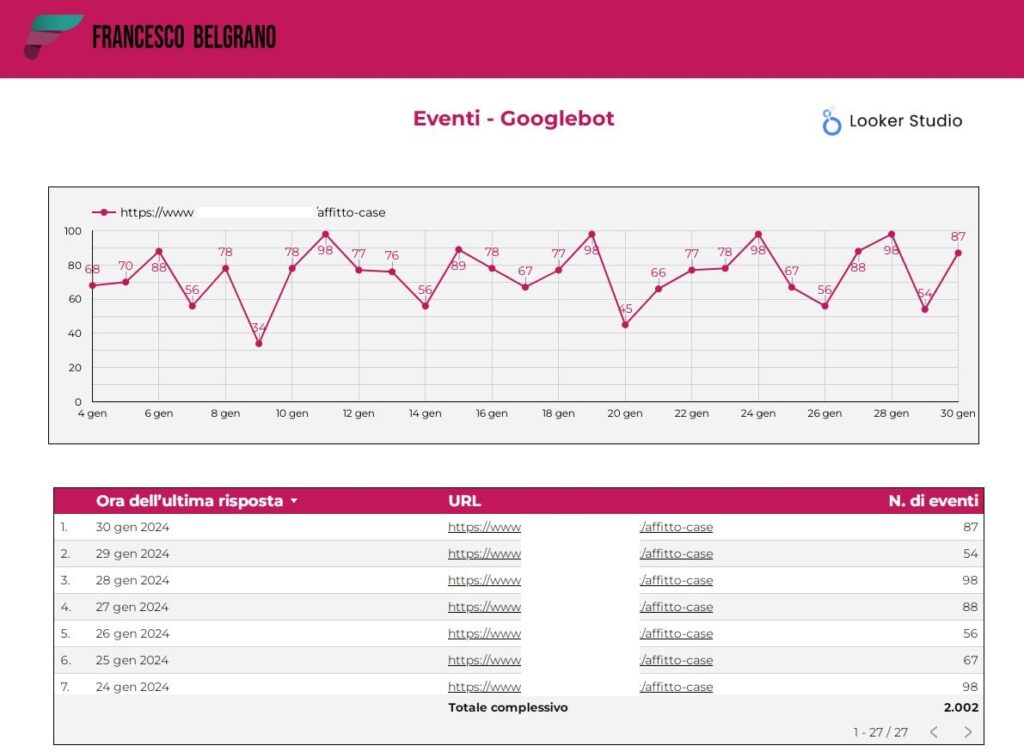
Monitoraggio di googlebot e degli altri crawler
Nei paragrafi successivi, esploreremo le aree chiave che i professionisti SEO dovrebbero monitorare per sfruttare al meglio l’analisi dei log file. Anche se Google è uno dei motori di ricerca più utilizzati, non esiste soltanto la scansione di googlebot, ma le nostre risorse possono essere scansionate da diversi crawler Google e No Google.
Googlebot è il crawler principale di Google, responsabile della scansione e dell’indicizzazione delle pagine web. Monitorare il suo comportamenti contribuisce al miglioramento SEO complessivo del sito, rendendo più efficace l’indicizzazione e aumentando la visibilità nei motori di ricerca.
La famiglia dei bot di Google
Non tutti i bot che hanno accesso al sito sono uguali: Google utilizza una varietà di crawler specializzati per diversi tipi di contenuti e dispositivi. Facciamo una panoramica con un elenco dettagliato.
Googlebot Desktop
- Descrizione: il crawler principale utilizzato da Google per scansionare la versione desktop dei siti web.
- Utilizzo: scansione di siti web ottimizzati per la visualizzazione su desktop.
Googlebot Smartphone
- Descrizione: bot dedicato alla scansione della versione mobile dei siti web.
- Utilizzo: essenziale per la mobile-first indexing, dove Google utilizza principalmente la versione mobile del contenuto per l’indicizzazione e il ranking.
Googlebot News
- Descrizione: il crawler specializzato nella scansione di siti web di notizie.
- Utilizzo: inclusione e aggiornamento dei contenuti su Google News.
Googlebot Images
- Descrizione: bot dedicato alla scansione delle immagini sui siti web.
- Utilizzo: migliora l’indicizzazione e il ranking delle immagini nei risultati di Google Immagini.
Googlebot Video
- Descrizione: il crawler addetto alla scansione dei contenuti video sui siti web.
- Utilizzo: aiuta nell’indicizzazione dei video per la ricerca video di Google.
Googlebot AdsBot
- Descrizione: crawler utilizzato per verificare la qualità delle pagine di destinazione degli annunci Google Ads.
- Utilizzo: garantisce che le pagine di destinazione degli annunci siano conformi alle policy di Google Ads.
Googlebot Mobile Ads
- Descrizione: simile a AdsBot, ma specificamente per le pagine di destinazione degli annunci mobili.
- Utilizzo: assicura che le pagine di destinazione degli annunci mobili siano conformi alle policy di Google Ads.
Googlebot App
- Descrizione: dedicato alla scansione delle app Android.
- Utilizzo: aiuta Google a scoprire e indicizzare i contenuti delle app Android.
Googlebot APIs
- Descrizione: crawler utilizzato per scansionare le API di un sito web.
- Utilizzo: assicura che le API siano indicizzabili e funzionino correttamente.
Googlebot E-commerce
- Descrizione: specializzato nella scansione di siti web di e-commerce.
- Utilizzo: ottimizza l’indicizzazione di prodotti e pagine di categoria su piattaforme di e-commerce.
Googlebot Jobs
- Descrizione: bot focalizzato sulla scansione delle offerte di lavoro pubblicate sui siti web.
- Utilizzo: aiuta nell’inclusione delle offerte di lavoro nei risultati di Google for Jobs.
Googlebot Shopping
- Descrizione: crawler dedicato alla scansione di dati strutturati relativi ai prodotti.
- Utilizzo: migliora l’inclusione e la visibilità dei prodotti nei risultati di Google Shopping.
Googlebot Hotel
- Descrizione: specializzato nella scansione di contenuti relativi agli hotel.
- Utilizzo: ottimizza l’indicizzazione delle pagine di hotel per Google Travel.
Altri Crawler non Google
Non esistono solo i bot di Google: altri motori di ricerca come Bing, Yandex e Baidu utilizzano i propri crawler, rispettivamente Bingbot, Yandexbot e Baiduspider, per scansionare e indicizzare i contenuti web.
Monitorare anche questi bot può offrire ulteriori opportunità per ottimizzare la visibilità online e raggiungere risultati importanti per il nostro business.
A cosa servono i Log?
Vediamo ora come i file di log possono aiutarci a comprendere vari aspetti cruciali del comportamento dei crawler e delle prestazioni del nostro sito web.
L’audit dei log del server consente di effettuare una valutazione fondamentale per chi si occupa di SEO e vuole strutturare una strategia basata su dati reali. Oltre a offrirci una visuale chiare sulle pagine più visitate del sito, i log hanno tantissime funzionalità a livello SEO:
- Identificare bot e richieste di spoofed search bot
- Velocità di scoperta degli URL
- Frequenza di scansione e ottimizzazione del Crawl Budget
- Profondità della Scansione e frequenza nelle subdirectories
- Pagine no index o bloccate dal robots.txt
- Ottimizzare le pagine lente e di grandi dimensioni
- Scoprire e gestire le orphan pages
- Risposte inconsistent response
- Audit redirect e risorse inesistenti
- Scansione del crawl hidden e spazi infiniti
- Full recrawl: quando e perché
Identificare bot e richieste di spoofed search bot
Prima di iniziare un’analisi dettagliata, è basilare identificare i bot legittimi dei motori di ricerca e distinguere le richieste provenienti dai bot falsificati (spoofed search bot) che possono imitare i veri crawler per scopi malevoli.
La log file analysis ci consente di rilevare queste attività sospette. Riconoscere e bloccare i bot dannosi è utile per proteggere il sito da potenziali minacce e garantire che il crawl budget sia utilizzato efficacemente dai veri motori di ricerca, evitando sprechi di risorse e migliorando l’efficienza complessiva dell’analisi SEO.
Velocità di scoperta degli URL
La velocità con cui Googlebot scopre nuovi URL è determinante per una rapida indicizzazione dei nuovi contenuti. Monitorando i file log, possiamo vedere quanto tempo il crawler impiega a trovare e scansionare nuove pagine dopo la loro creazione. Ottimizzare la struttura del sito e i link interni può accelerare questo processo, migliorando il tempo di indicizzazione.
Frequenza di scansione e ottimizzazione del crawl budget
L’analisi dei file di log permette di capire con quale frequenza i diversi tipi di contenuto vengono scansionati dai vari user-agent. Questa informazione è utile per ottimizzare il sito ad esempio, possiamo garantire che i contenuti dinamici e frequentemente aggiornati ricevano l’attenzione necessaria.
La frequenza di scansione delle pagine aggiornate è un indicatore della salute del sito. Se Googlebot visita spesso le pagine appena modificate, significa che il sito è considerato autorevole e aggiornato. Monitorando questi dati, possiamo fare in modo che le pagine chiave siano sempre scansionate tempestivamente.
Identificare e rimuovere le pagine di basso valore dal budget di scansione è una strategia efficace per migliorare l’efficienza dell’accesso al sito, assicurando che le risorse del crawler siano impiegate sulle pagine che contano di più.
Profondità della scansione e frequenza nelle subdirectories
La profondità della scansione si riferisce a quanti livelli di pagine il bot esplora all’interno del sito. Idealmente, le pagine più importanti dovrebbero essere raggiungibili con pochi click dalla homepage. I log aiutano a capire se Googlebot raggiunge tutte le pagine desiderate e se l’architettura del sito facilita una scansione profonda ed efficace.
Analizzare la frequenza con cui Googlebot scansiona le diverse subdirectories del sito può rivelare se ci sono sezioni del sito che vengono trascurate. Ottimizzare la struttura delle subdirectories e i link interni può assicurare che tutte le parti del sito ricevano l’attenzione necessaria dai crawler, garantendo una copertura completa e migliorando i percorsi di navigazione.
Pagine no index o bloccate dal robots.txt
È importante assicurarsi che le pagine che non devono essere indicizzate siano correttamente segnalate come no index o bloccate da robots.txt. Possiamo verificare se i crawler stanno cercando di accedere a queste pagine che potrebbero essere bloccate e di apportare le necessarie correzioni. Questo aiuta a mantenere un sito ben ottimizzato e a evitare che il crawl budget venga sprecato su pagine non rilevanti.
Ottimizzare le pagine lente e di grandi dimensioni
Le dimensioni delle pagine scansionate dai bot sono un metro di valutazione utile per comprendere l’uso delle risorse del sito. Pagine troppo grandi possono rallentare la scansione e consumare eccessivamente il crawl budget. Ottimizzare le dimensioni delle pagine per renderle più leggere e facilmente scansionabili migliora significativamente l’efficienza della scansione.
Parallelamente, le pagine lente e i contenuti di basso valore influiscono negativamente sull’esperienza utente e sul ranking del sito. Utilizzando i file di log, è possibile identificare queste pagine e prendere misure per migliorare le loro performance. Migliorare la velocità di caricamento delle pagine e la qualità dei contenuti è strategico per mantenere un sito performante e rilevante.
Scoprire e gestire le orphan pages
Le orphan pages, ovvero pagine non collegate da altre pagine del sito, rappresentano un problema significativo per l’indicizzazione. Queste pagine possono rimanere invisibili ai crawler, compromettendo la completa scansione del sito. L’analisi dei file di log permette di scoprire queste pagine orfane.
Una volta identificate, è fondamentale collegarle adeguatamente all’interno della struttura del sito per garantire che ricevano l’attenzione necessaria dai crawler e vengano indicizzate correttamente. Ottimizzare la rete di link interni e assicurarsi che ogni pagina importante sia facilmente raggiungibile è un fattore decisamente importante.
Identificazione degli status code
Gli status code HTTP forniscono informazioni cruciali sulle risposte del server alle richieste dei motori di ricerca. Analizzare questi codici ci permette di identificare eventuali problemi come errori 404 (pagina non trovata) o 500 (errore interno del server), che possono impedire una corretta indicizzazione delle pagine e sulle prestazioni del sito.
Risposte inconsistent response
Le risposte incoerenti del server, come variazioni nei codici di stato per la stessa pagina, possono indicare problemi di stabilità o configurazione. Monitorare e risolvere queste inconsistenze è fondamentale per garantire che i crawler ricevano sempre risposte accurate e coerenti.
Audit redirect e risorse inesistenti
Gli audit dei redirect e delle risorse inesistenti sono essenziali per mantenere un sito sano. I file di log aiutano a identificare catene di redirect e risorse mancanti, permettendo di correggere questi problemi e migliorare la navigazione e l’indicizzazione del sito.
Scansione del crawl hidden e spazi infiniti
Il crawl hidden e gli spazi infiniti sono problematiche che possono impedire al crawler di scansionare correttamente il sito. Questi problemi si verificano quando ci sono URL infiniti generati dinamicamente o contenuti nascosti dietro script complessi.
Monitorare e risolvere queste questioni attraverso l’analisi dei log è fondamentale per garantire una scansione completa ed efficiente.
Full recrawl: quando e perché
Un full recrawl del sito da parte dei bot può essere necessario in caso di significative modifiche strutturali o di contenuto. Questo processo assicura che tutte le pagine vengano rianalizzate e aggiornate nei risultati di ricerca. Pianificare e monitorare questi recrawl attraverso i file di registro ci aiuta a mantenere il sito sempre ottimizzato.
Best Practices per la SEO Log Analysis
Implementare le best practices è essenziale per ottenere il massimo beneficio dalla SEO tecnica. Ecco alcune pratiche consigliate per un’analisi efficace e approfondita:
- Accesso regolare e utilizzo di strumenti avanzati
- Segmentazione dei dati e monitoraggio regolare
- Alert automatici e documentazione
1. Accesso regolare e utilizzo di strumenti avanzati
Assicurati di avere accesso continuo ai file di log del server. Utilizza il pannello di controllo dell’hosting, FTP o SSH per scaricare regolarmente i log file e garantire che i dati siano sempre aggiornati
Sfrutta strumenti di analisi dei log avanzati come Splunk, ELK Stack (Elasticsearch, Logstash, Kibana) o Screaming Frog SEO Log File Analyzer. Questi strumenti automatizzano la raccolta e analisi dei file log, riducendo il rischio di errori manuali e risparmiando tempo prezioso.
2. Segmentazione dei dati e monitoraggio regolare
Dividi e segmenta i dati in base a criteri significativi come tipo di contenuto, directory e user-agent. Questo permette di avere una visione più chiara e mirata delle performance del sito e del comportamento dei crawler.
Esegui controlli regolari, almeno una volta al mese, per identificare nuovi problemi o cambiamenti nel comportamento dei crawler. La revisione periodica dei log file aiuta a mantenere il sito ottimizzato e a risolvere eventuali problematiche tempestivamente.
3. Alert automatici e documentazione
Imposta alert automatici per essere avvisato in caso di anomalie significative, come un improvviso aumento di errori 4xx o 5xx. Questo consente di intervenire rapidamente e mitigare i problemi prima che abbiano un impatto negativo sulle performance del sito.
Mantieni una documentazione aggiornata delle modifiche e degli interventi effettuati. Traccia ogni azione in ordine temporale per avere un quadro chiaro dell’evoluzione del sito e delle sue prestazioni nel tempo. Questo facilita l’identificazione di pattern e la diagnosi di problemi.
Importanza della registrazione sequenziale e cronologica delle operazioni
La registrazione sequenziale e cronologica delle operazioni è importante per ottenere una visione accurata e completa delle attività sul sito. Questo tipo di registrazione consente di tracciare ogni azione in ordine temporale, facilitando l’identificazione di pattern e la diagnosi di problemi.
Inoltre, una registrazione accurata aiuta a correlare eventi diversi, come picchi di traffico con errori di server, migliorando la capacità di risolvere rapidamente le problematiche e ottimizzare le performance del sito.
Perché implementare la Log Analysis nella strategia SEO?
Come abbiamo visto, non si può prescindere dalla log analysis per una strategia SEO efficace. Comprendere i passaggi del crawler è fondamentale per risolvere problematiche tecniche e ottenere un vantaggio competitivo. Dalla scansione all’indicizzazione, fino al posizionamento nei motori di ricerca, ogni aspetto del sito può essere ottimizzato grazie all’utilizzo dei dati forniti dai log file.
Gestire al meglio le risorse che ospita il nostro sito, identificare e correggere errori, e garantire che le pagine più importanti siano scansionate e indicizzate correttamente sono tutti obiettivi raggiungibili con un’analisi dei log ben condotta. Investire tempo e risorse in questa pratica non solo migliora la visibilità online, ma assicura anche un’esperienza utente ottimale, rendendo il sito più performante e competitivo nel lungo termine.